DATABASE
[정규화]란 무엇인가
Haksae
2022. 4. 1. 10:31
1. 정규화 (Normalization)
정규화란 관계형 데이터베이스의 설계에서 데이터 간의 중복을 최소화되게 데이터를 구조화하는 프로세스를 뜻한다.
- 정규화는 함수적 종속성을 이용해서 연관성이 있는 속성들을 분류하고, 각 릴레이션들에서 이상현상이 생기지 않도록 하는 과정이다.
- 이 과정은 큰 테이블을 연관이 있는 컬럼들만 쪼개서, 중복이 없는 형태로 작게 여러 테이블로 쪼개 나가는 과정을 가진다.
1.1. 정규화의 목적
- 불필요한 데이터를 제거하고 데이터 중복을 최소화하기 위해서
- 데이터베이스 구조 확장 시, 재 디자인을 최소화하기 위해서
- 무결성 제약 조건의 시행을 간단하게 하기 위해서
- 테이블 구성을 논리적이고 직관적으로 만들어, 이상현상을 방지하기 위해서
1.2 이상현상(Anomaly)
- 삽입 이상(insertion anomaly) : 데이터를 저장할 때 원하지 않는 정보가 함께 삽입되는 경우
- 갱신 이상(update anomaly): 중복된 튜플 중 일부의 속성만 갱신시킴으로써 정보의 모순성이 발생하는 경우
- 삭제 이상(delete anomaly): 튜플을 삭제함으로써 유지되어야하는 정보까지도 연쇄적으로 삭제되는 경우
⇒ 이상 현상이 발생하는 원인은 관련없는 속성들을 다 모아서 하나의 릴레이션으로 만들었기 때문
⇒ 이상 현상을 방지하기 위해 정규화를 하는 것
⇒ 정규화를 통해 릴레이션을 관련이 있는 속성들로만 구성되는 작은 여러 개의 릴레이션으로 분해(decomposition)해야 한다.
1.3 함수적 종속성 (Functional Dependency)
- 데이터베이스의 릴레이션에서 두 개의 속성(Attribute) 집합 간 제약의 일종
- 데이터들이 어떤 기준 값에 의해서 항상 종속이 되는 현상을 뜻한다.

- 정규화시, 일반적으로 속성들 간의 관련성을 판단하여, 하나의 릴레이션에는 하나의 함수적 종속성만이 존재하도록 정규화를 하게 된다.
<정규화가 꼭 답은 아니다>
- 3NF을 만족하면 정규화 되었다고 한다.
- 정규화가 잘 되면, IUD에서는 훨씬 좋은 모습을 보이지만, 분리된 테이블에 대한 통합적인 뷰를 보아야할 때 조인이 많이 이루어지므로 cost가 더욱 발생하고, 일부 쿼리에 대해서는 효율이 나빠질 수 있다.
- Analytic query를 주로 실행하는 OLAP 애플리케이션인 경우 성능 향상을 위해 낮은 수준의 정규화를 추구하기도 한다.
- Denormalization : 일부 쓰기 성능의 손실을 감수하고 데이터를 묶거나 데이터의 복제 사본을 추가함으로써 데이터베이스의 읽기 성능을 개선하려고 시도하는 과정
<기본 정규형과 고급 정규형>
- 기본 정규형으로는 제 1-3 정규형이 있고, 제 4 정규화 이후로는 고급 정규형으로 분류된다.
- 제 1-3 정규화가 데이터 속성들 간의 종속성을 고려한 정규화라면, 제 4 정규화 이후로는 튜플이 생성될 때 관계까지 고려하여 정규형 폼을 만드는 것이다. 그러나 제 1-3 정규화 만으로도 무리없이 데이터베이스 설계가 가능하다.
- 고급 정규형은 너무 복잡하므로 본 글에서는 제 1-3 정규화만 다루겠다.
2. 제 1 정규화 (1NF, First Normal Form)
제 1 정규화는 테이블의 컬럼이 원자값(Atomic Value, 하나의 값)을 갖도록 테이블을 분해하는 것이다.
- 같은 성격과 내용의 컬럼이 연속적으로 나타나는 컬럼이 존재할 때, 해당 컬럼을 제거하고 기본 테이블의 PK를 추가해 새로운 테이블을 생성하고, 기존의 테이블과 1:N 관계를 형성


- 위의 제 1 정규화 예시를 살펴보자
- 위의 테이블의 취미 필드를 보면, 여러 개의 값들이 존재하는 경우가 있다. 이는 제 1 정규형을 만족하지 못하고 있는 상황이다.
- 그렇기 때문에 이를 제 1 정규화하여 두번째 그림과 결과를 만들어낸다.


- 조금은 더 복잡한 제 1 정규화 예시를 살펴보자
- 판매 테이블에는 여러 필드들이 존재하는데, 파란색 부분이 중복되어 있는 상태이다.
- 이를 제 1 정규화 과정을 통해 다른 테이블로 구분해주고, FK값을 설정하고 1:N 관계를 설정한 것이다.
3. 제 2 정규화 (2NF, Second Normal Form)
제 2 정규화란, 제 1 정규화를 진행한 테이블에 대해 완전 함수 종속을 만족하도록 테이블을 분해하는 것이다.
- PK가 여러 키로 구성된 복합키(Composite Primary Key)로 구성된 경우가 2차 정규화의 대상이 된다.
- 복합키 전체에 의존하지 않고 복합키의 일부분에만 종속되는 속성들이 존재할 경우 (즉, 부분적 함수 종속 관계) 이를 분리하는 것이다.


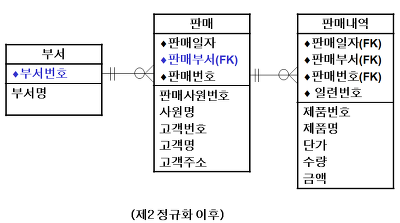
- 위의 제 2 정규화 예시를 살펴보자
- 첫 번째 사진을 보면 판매부서와 부서명이 불일치하는 상황임을 알 수 있다.
- 두 번째 사진을 살펴보면, 이러한 불일치가 완전 함수 종속이 되지 않았기 때문임을 알 수 있다. (판매부서와 부서 명 간에)
- 부서와 판매 테이블을 나눔으로 위의 문제를 해결해주는 것을 제 2 정규화라고 한다.


- 제 2 정규화의 예시를 하나 더 살펴보자
- 첫번째 사진의 수강강좌 테이블에서 기본키는 (학생번호, 강좌이름)으로 복합키이다. 그리고 (학생번호,강좌이름)인 기본키는 성적을 결정하고 있다. (학생번호,강좌이름) -> (성적)
- 그런데 여기서 강의실이라는 컬럼은 기본키의 부분집합인 강좌 이름에 의해 결정될 수 있다. (강좌이름) -> (강의실)
- 즉, 기본키(학생번호, 강좌이름)의 부분키인 강좌이름이 결정자이기 때문에, 수강강좌의 테이블의 경우 두번째 사진과 같이 기존의 테이블에서 강의실 테이블을 분해하여 별도의 테이블로 관리하여야한다.
4. 제 3 정규화 (3NF, Third Normal Form)
제 3 정규화란, 제 2 정규화를 진행한 테이블에 대해 이행적 종속을 없애도록 테이블을 분리하는 것이다.
- 함수적 종속 관계가 슈퍼키에서 시작하거나 prime attribute(candidate key에 포함된 attribute)로 끝나야한다.
- 제 3 정규화는 PK에 의존하지 않고 일반컬럼에 의존하는 컬럼들을 분리한다.


- 제 3 정규화의 예시를 살펴보자
- 첫번째 사진에서 계절학기 테이블에서 학생 번호는 강좌 이름을 결정하고 있고, 강좌 이름은 수강료를 결정하고 있다.
- 그렇기 때문에 이를 두번째 사진과 같이 (학생번호, 강좌 이름) 테이블과 (강좌이름, 수강료) 테이블로 분해해야한다.
- 왜 해야하죠? 이행적 종속을 제거하는 이유를 본 예시에서 찾아본다면.. 가령 501번 학생이 수강하는 강좌가 자료구조로 변경되면 수강료까지 변경해줘야한다. 물론 변경이 가능하지만 번거롭기 때문에 제 3 정규화를 하는 것이다.
5. BCNF (Boyce-Codd Normal Form) 정규화
BCNF 정규화란, 제 3 정규화를 진행한 테이블에 대해 모든 결정자가 후보키가 되도록 테이블을 분해하는 것이다.
- BCNF는 3NF에서 조금 더 강화된 버전 (3.5NF라고도 불림)
- 모든 함수 종속 관계 (X → Y)에서 X로 가능한 집합의 속성이 모두 슈퍼 키이면 BCNF을 만족한다.


참고자료
https://mangkyu.tistory.com/110
https://myeonguni.tistory.com/210