
한 걸음씩 기록하며
#.4 Stack & Queue 본문
1. Stack

- 후입선출(Last-In First-Out / LIFO) : 나중에 들어온 데이터가 먼저 나감
- 후임선출 방식의 자료구조로, 가장 나중에 쌓은 데이터를 가장 먼저 빼낼 수 있는 데이터 구조
- 대표적인 스택의 활용으로는, 컴퓨터 내부의 프로세스 구조의 함수 동작 방식이 있다.
- 장점
- 구조가 단순해서 구현이 쉽다.
- 데이터 저장/ 읽기 속도가 빠르다
- 단점
- 데이터 최대 개수를 미리 정해야한다.
- 저장 공간의 낭비가 발생할 수 있다.
- 미리 최대 개수만큼의 저장 공간을 확보해야한다.
- 스택은 단순하고 빠른 성능을 위해 사용되므로, 보통 배열 구조를 활용해서 구현하는 것이 일반적이다. (이 경우 위에서 열거한 단점이 발생한다.)
2. Queue
1) Queue
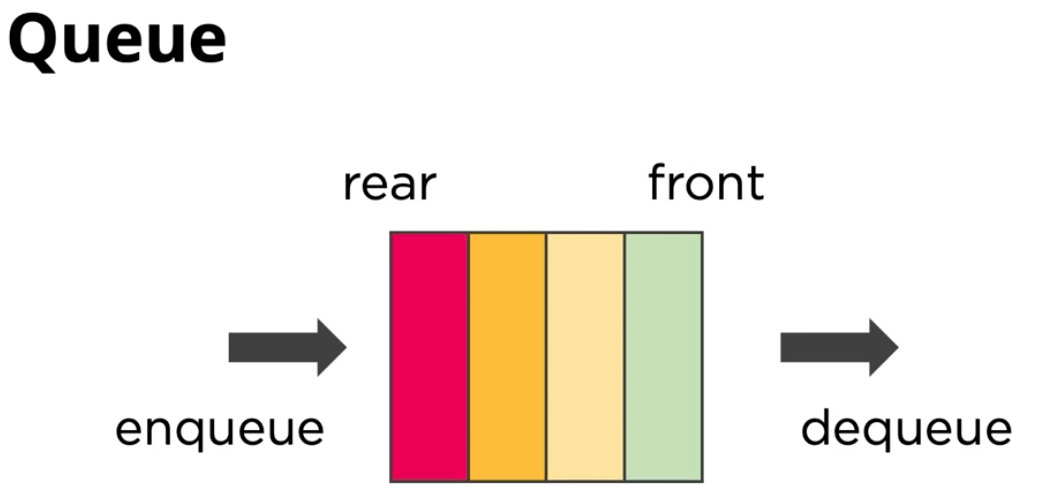
- 선입선출 (First-In Fast-Out / FIFO) : 먼저 들어온 데이터가 먼저 나간다.
- 가장 먼저 넣은 데이터를 가장 먼저 꺼낼 수 있는 구조로, 스택과 꺼내는 순서가 반대이다.
- Enqueue : 큐에 데이터를 넣는 기능
- Dequeue : 큐에서 데이터를 꺼내는 기능
2) Linear Queue (선형 큐)

- 선형 배열을 사용하여 구현된 큐
- 삽입을 위해서는 계속해서 요소들을 이동시켜야한다.
- front, rear는 증가만 하는 방식, 실제로는 front 앞쪽에 공간이 있더라도 삽입을 할 수 없는 경우가 발생할 수 있다.
3) Circular Queue(원형 큐)
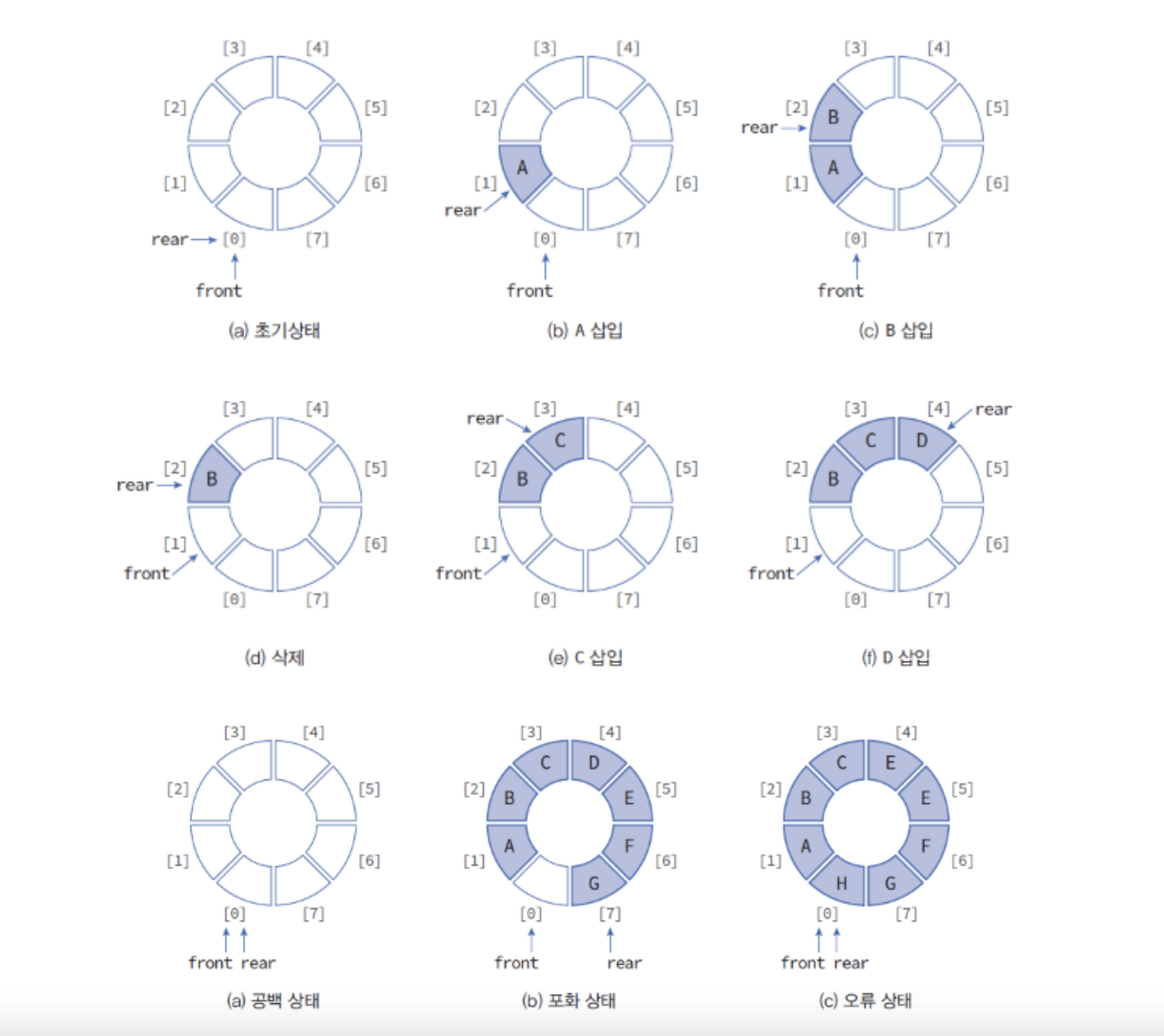
- 선형 큐의 단점을 보완하여, 원형으로 구현된 큐이다.
- front는 맨 첫번째 요소 바로 앞을 가리키고, rear는 마지막 요소를 가리킨다.
- empty는 front == rear를 뜻하고, full은 front == (rear+1) % MAX_QUEUE_SIZE이다.
- 공백 상태와 포화 상태를 구분하기 위해 하나의 공간을 비워둔다.
4) 선형 큐와 원형 큐의 비교, 장단점
- 선형 큐
- 선형 큐의 경우 배열로 구현하기 때문에 속도가 빠른 장점이 있다.
- 데이터를 삽입할 때마다 요소들을 이동시켜야하는 번거로움이 있고, 인덱스를 감소시키지 않는 방식이기에 공간 효율이 떨어진다.
- 그러나 크기가 제한되어 있다는 점과 오버플로우(큐가 꽉차서 더이상 자료가 들어갈 수 없는 상태)가 발생한다.
- 원형 큐
- 크기에 제한이 없고, 공백상태와 포화상태를 쉽게 알 수 있다.
- 선형 큐의 비해 속도가 느리다.
- 큐의 공통된 장점
- 데이터 접근, 삽입 삭제가 빠르다.
- front, rear의 위치로 데이터 삽입 삭제가 이루어지기 때문에, 시간 복잡도는 O(1)이다.
- 데이터가 입력된 시간 순서대로 처리해야할 필요가 있는 상황에서 사용하기 좋다.
- 데이터 접근, 삽입 삭제가 빠르다.
참고자료
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=rlaauddlf200&logNo=30140551855
'자료구조' 카테고리의 다른 글
| #. 6 Tree (0) | 2022.03.14 |
|---|---|
| #.5 Deque (0) | 2022.03.09 |
| #.3 Linked List (0) | 2022.03.09 |
| #.2 ArrayList (0) | 2022.03.09 |
| #. 1 Data Structure (0) | 2022.03.09 |
'자료구조' Related Articles
more




Comments